
Hey, do you want to know what Robots.txt is and why It is Important in SEO? If yes, then read this blog till the end.
What is Robots.txt
Robots.txt is a text file that a website owner creates to tell search engine crawlers how to crawl web pages on the website. You can also use this file to prevent search engines from crawling specific web pages of your website. When uploading a robots.txt file or making changes to this file, you need to be very careful because it could harm your website rankings. The robots.txt file is super important in SEO.
How Does a Robots.txt file look like
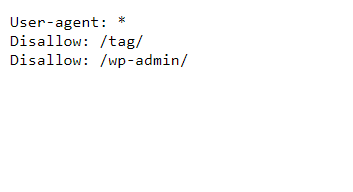 Things you should keep in mind while creating a Robots.txt file
Things you should keep in mind while creating a Robots.txt file
- With the help of the Robots.txt file, you can instruct Search Engines like Google to not access certain pages of your websites. You can also use this file to prevent duplicate content and give search engines like Google and Bing information on how they should crawl your website.
- Always be very careful while making changes to the Robots.txt file because it could make some pages of your website inaccessible to Search Engine, which will impact your website traffic.
- The Robot.txt file is a very important file from the SEO perspective because it tells crawlers how to crawl your website properly.
Why Robots.txt is important
Robots.txt file is not important for all websites, especially small websites. But it doesn’t mean you shouldn’t have one. Having a robots.txt file gives you more control over how search engine crawlers should crawl your website.
1. Preventing Indexing of Less Important pages or (Resources)
With the help of robots.txt, you can prevent crawlers from crawling some web pages on your website, and you can also use it to prevent Indexing of your multimedia resources.
2. Utilize Crawl Budget
If all important pages of your website are not getting indexed, then it may be happening because of the crawl budget. With the help of robots.txt, you can block all the unimportant pages of your website so that search engine bots like Google or Bing bot spend more time on important pages of your website.
3. Block Pages that are not important for users
Lots of times, we have some pages on our website that contain sensitive content or have content you think is not important for users, and then you can block them by using robots.txt.
For example, if you have a login page, then these types of pages have to exist. You don’t want to index them, so in this case, you can use robots.txt to block this page for crawlers.
Robots.txt Syntax
There are four common terms that you will see in a Robots.txt file.
1. User-agent:
A specific crawler or a Search Engine to which we give instructions.
2. Disallow:
It is an instruction or command that we use to tell search engine crawlers not to crawl a particular page.
3. Crawl-delay:
It is a command that we give to the crawler to determine how many seconds a crawler should wait before crawling the web page. (Googlebot does not follow this command)
4. Allow:
It is a command that instructs Google Bot to crawl a web page even if its parent page is disallowed. It is only applicable to Googlebot.
How to find the robots.txt file
If you want to know if your website has a robots.txt file or not, you can check that by using this yourdomain.com/robots.txt.
Here, replace yourdomain.com with your website URL and search it on any web browser. After that, if you get a file like in the picture, then it means your website has a robots.txt file.
If you don’t have a robots.txt file, then you can easily create one for your website. To do that, first open a new .txt file. Now start typing
user-agent: *
Now, if you want to disallow your admin directory for all crawlers, then type
Disallow: /admin/
Once you have done that, your robots.txt file will look something like this.
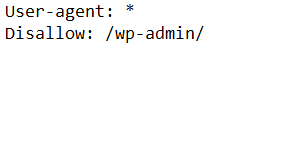 Now If you want you can also add more instructions to your .txt file. Now, if you are looking for an easier way of creating a robots.txt file for your website, then you can also use a robots.txt generator tool. With the help of a good tool, you can easily create the robots.txt file, and it will also minimize the small syntax-related errors, which are very important.
Now If you want you can also add more instructions to your .txt file. Now, if you are looking for an easier way of creating a robots.txt file for your website, then you can also use a robots.txt generator tool. With the help of a good tool, you can easily create the robots.txt file, and it will also minimize the small syntax-related errors, which are very important.
Where to upload your robots.txt file
To upload robots.txt, open the c panel of your Hosting, then go to the file manager. The next step is to find the public_html folder and then upload your .txt file here.
After finishing this process, you can check your robots.txt file by searching yourdomain.com/robots.txt in the search box of web browsers.
If you want to upload a robots.txt file for your subdomain, then upload it to the root directory of your subdomain. To access robotos.txt of your subdomain, type blog.yourdomain.com/robots.txt in the search bar of your web browser.
Best Practices
Here are the things you should avoid while creating robots.txt.
1. Use Wildcards
Use wildcards (*) to apply instructions to all user agents, and you can also use them to match URL Patterns when declaring directives.
2. To specify the end of the URL use “$”
To specify the end of the URL use “$”
Ex. If you have lots of PDF files on the website and you don’t want search engines to index them, then you can add this syntax on the 30th of our robots.txt file.
User-agent: *
Disallow: /*.pdf$
So with this, the search engine can’t access any URL ending with .pdf.
3. Use Comments to explain your robots.txt file to humans
With the help of comments, your team or developers can understand your robots.txt file. To add comments to your file, start the line with a hash (#).
All crawlers will ignore all lines that are starting from #.
So that’s it from this blog. I hope you enjoyed this. If you liked this article on What is Robots.txt and Why It is Important in SEO, then please share it with your friends and social media followers. If you need any clarification related to this article, then feel free to ask in the comments section below.